Comprender la IA a menudo resulta confuso porque términos como machine learning, deep learning, transformers y NLP se utilizan indistintamente. En esta guía verás cómo realmente se conectan, paso a paso, y cómo los transformers se convirtieron en la base de los LLMs modernos como ChatGPT. Si no entiendes la estructura, la IA parece abstracta; una vez que la comprendes, todo se vuelve lógico...
Comprender la IA a menudo resulta confuso porque términos como machine learning, deep learning, transformers y NLP se utilizan indistintamente. En esta guía verás cómo realmente se conectan, paso a paso, y cómo los transformers se convirtieron en la base de los LLMs modernos como ChatGPT. Si no entiendes la estructura, la IA parece abstracta; una vez que la comprendes, todo se vuelve lógico...





La IA no es magia — ¿De qué está realmente hecha? Inteligencia Artificial, Explicada con Claridad

Frank Arellano
Founder of Plexotrade LLCSi estás intentando entender los Modelos de Lenguaje de Gran Escala (LLMs), hay una confusión que debes aclarar de inmediato:
Inteligencia Artificial → Machine Learning → Redes Neuronales → Redes Neuronales Profundas / Deep Learning → Arquitectura Transformer
(El NLP es una disciplina aplicada separada que opera a lo largo de todo el stack)
- Son capas de un stack.
- Cada una se construye sobre la anterior.
- Cada una cumple un papel diferente.
Si las mezclas todas, todo se vuelve confuso. ¿Por qué la mayoría de las explicaciones sobre IA parecen confusas? Porque omiten la estructura. Una vez que ves la jerarquía con claridad, todo se vuelve lógico.
Cómo los Transformers Dieron Origen a ChatGPT y a los Modelos Modernos de Lenguaje
Antes de los transformers, los modelos de IA ya existían y se utilizaban activamente en tareas de lenguaje. Sistemas como las redes neuronales recurrentes (RNNs) y las redes de memoria a largo corto plazo (LSTMs) impulsaban:
- Traducción
- Reconocimiento de voz
- y predicción de texto.
Sin embargo, tenían dificultades con las dependencias lingüísticas de largo alcance y eran difíciles de escalar de forma eficiente. El paradigma cambió en 2017 cuando Google introdujo la arquitectura Transformer en el artículo “Attention Is All You Need.”
Al reemplazar la recurrencia con auto-atención, los transformers permitieron una paralelización masiva, un mejor manejo del contexto y una escalabilidad sin precedentes. Este cambio arquitectónico transformó fundamentalmente la IA, haciendo posibles los actuales modelos de lenguaje de gran escala.
Las dependencias de largo alcance son situaciones en las que el significado de una palabra depende de otra palabra que aparece muy lejos dentro de la oración. En el lenguaje humano, las relaciones importantes a menudo están separadas por muchas palabras.
Por ejemplo:
"The book that the professor who won the award recommended was fascinating."
La palabra “was” depende de “book”, no de “professor” ni de “award.” Pero “book” aparece mucho antes en la oración. Esa distancia es una dependencia de largo alcance.
Los transformers utilizan auto-atención, lo que permite que cada palabra “observe” directamente a todas las demás palabras de la oración de forma instantánea. En lugar de pasar la información paso a paso, el modelo calcula las relaciones en paralelo.
Eso significa:
- “Was” puede atender directamente a “book”
- Incluso si 30 palabras las separan
- Sin perder información debido a la distancia
1. Transformer Es una Arquitectura de Red Neuronal Profunda
Un transformer es un diseño específico de una red neuronal profunda.
Define:
- Cómo fluye la información a través de las capas
- Cómo funcionan los mecanismos de atención
- Cómo se modelan las relaciones entre tokens
No está separado de las redes neuronales.
Es un tipo de red neuronal.
Un transformer no está fuera de las redes neuronales. Es una forma especializada de ellas.
Su innovación definitoria es la auto-atención, que permite al modelo ponderar la importancia de cada token en relación con todos los demás tokens dentro de una secuencia.
2. Deep Learning Utiliza Redes Neuronales Profundas
El deep learning se refiere a redes neuronales con múltiples capas que aprenden representaciones jerárquicas a partir de datos.
La palabra “deep” simplemente significa:
- Muchas capas apiladas
- Abstracción de características capa por capa
- Extracción progresiva de patrones
Los transformers son redes neuronales profundas basadas en mecanismos de atención en lugar de recurrencia o convolución, diseñadas para modelar patrones complejos en secuencias.
La profundidad permite la abstracción. La abstracción permite la inteligencia.
3. Las Redes Neuronales Forman Parte del Machine Learning
El machine learning es el campo más amplio en el que los modelos aprenden patrones a partir de datos en lugar de ser programados explícitamente.
El deep learning es un subconjunto del machine learning centrado específicamente en redes neuronales.
Así comienza a formarse la jerarquía:
- Machine Learning (campo científico y marco metodológico)
- Redes Neuronales (familia de modelos de machine learning)
- Redes Neuronales Profundas / Deep Learning (paradigma de modelado con redes neuronales dentro del machine learning)
- Arquitectura Transformer (arquitectura específica de red neuronal profunda)
El machine learning es el paraguas. El deep learning es una rama. Los transformers son un diseño dentro de esa rama.
Esta analogía simple puede ayudar:
Machine Learning = campo de la ingeniería civil
Redes Neuronales = tipo de material de construcción
Deep Learning = métodos de construcción de rascacielos
Transformer = diseño específico de rascacielos
4. Cómo Este Stack Crea los LLMs
Un Modelo de Lenguaje de Gran Escala (LLM) se crea cuando:
- Una arquitectura transformer
- Se entrena utilizando técnicas de optimización de machine learning
- Sobre cantidades masivas de datos de texto
- Utilizando recursos computacionales a gran escala
El stack completo se ve así:
| Capa | Rol |
| Machine Learning | Proporciona métodos de optimización y el marco de aprendizaje |
| Redes Neuronales | Proporcionan el marco de modelado matemático |
| Redes Neuronales Profundas / Deep Learning | Utiliza redes neuronales profundas para aprender representaciones jerárquicas |
| Arquitectura Transformer | Define el diseño específico de la red neuronal |
| Entrenamiento a Gran Escala | Preentrena el transformer en conjuntos de datos masivos utilizando cómputo a gran escala, produciendo un modelo fundacional que puede adaptarse o ajustarse posteriormente en un LLM. |
En resumen:
Arquitectura Transformer + Objetivo de Entrenamiento (p. ej., predicción del siguiente token) + Conjunto de Datos Masivo + Cómputo a Gran Escala = LLM
La arquitectura sin datos está vacía. Los datos sin cómputo son inertes. El cómputo sin estructura es inútil.
Estas tres fuerzas — datos, arquitectura y potencia computacional — han convergido en el momento preciso para hacer posibles modelos de lenguaje de gran escala altamente capaces.
Los conjuntos de datos masivos proporcionan la materia prima, las arquitecturas transformer proporcionan la estructura, y los procesadores modernos suministran la potencia computacional necesaria para entrenarlos a gran escala.
En particular, los procesadores diseñados para computación paralela son esenciales, porque entrenar estos modelos implica realizar miles de millones de operaciones matemáticas simultáneamente.
Hoy en día, el nombre más reconocido en hardware de computación para IA es Nvidia, cuyas GPUs se han convertido en la columna vertebral del entrenamiento de IA a gran escala.
Para ver una implementación práctica a gran escala, observa cómo Salesforce aplica IA en su ecosistema:
- ¿Qué es el trabajo digital? — Agentes de IA inteligentes
- El blueprint agent-first — 5 características de una empresa Agentforce
Un GPT (Generative Pretrained Transformer) es un tipo específico de modelo de lenguaje basado en transformers entrenado con un objetivo generativo (una familia de LLMs).
Dónde Entra el NLP en la Imagen
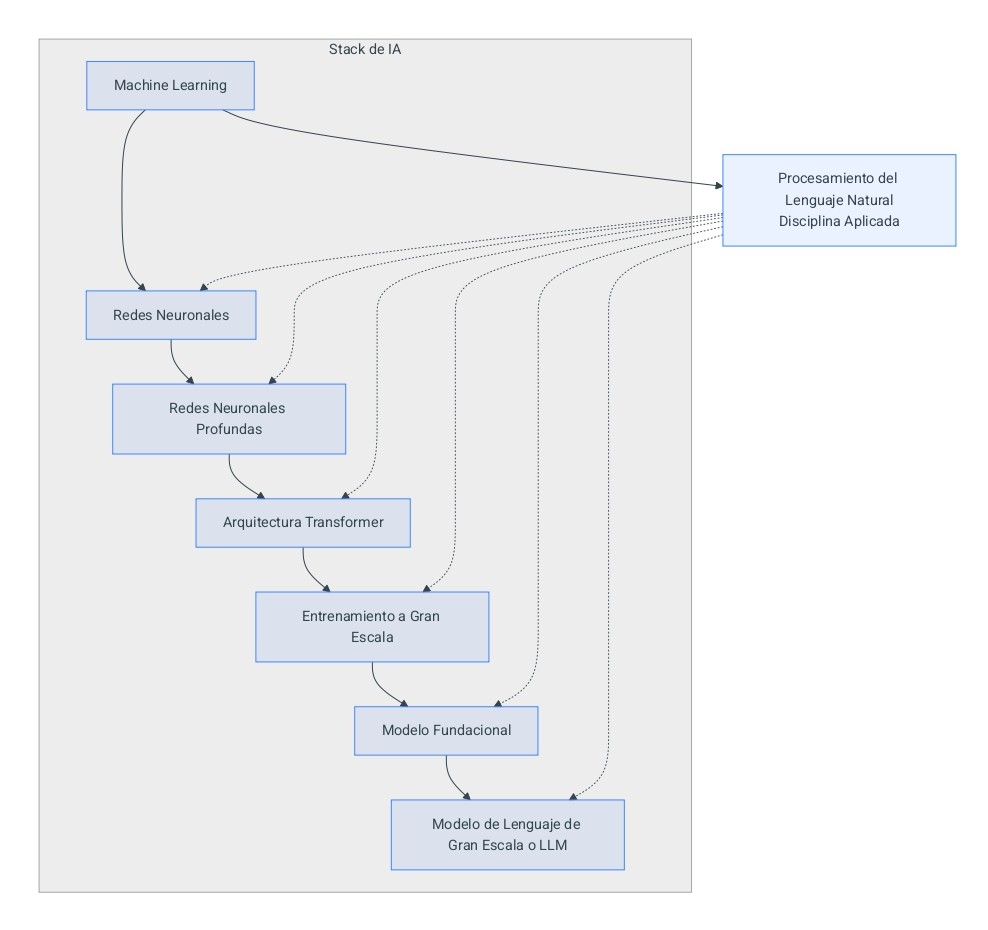
Ahora introducimos otra capa:
Procesamiento de Lenguaje Natural (NLP)
Piensa en NLP como el campo enfocado en el lenguaje donde los métodos de machine learning se aplican para comprender, analizar y generar lenguaje humano.
Las técnicas de NLP se aplican antes del entrenamiento, durante el entrenamiento y después del entrenamiento.
El NLP no es el motor. Define cómo el motor interactúa con el lenguaje.
1. Preparación de Datos y Tokenización
Antes de que comience el entrenamiento, las técnicas de NLP procesan el lenguaje humano en una forma que los modelos puedan aprender.
Los ejemplos incluyen:
- Limpieza y normalización de texto
- Segmentación de oraciones
- Tokenización en subpalabras o tokens
- Manejo de puntuación, mayúsculas y texto multilingüe
Este es el preprocesamiento clásico de NLP.
Sin esta etapa, el lenguaje en bruto es demasiado irregular y ruidoso para un aprendizaje efectivo.
El lenguaje debe estructurarse antes de poder aprenderse.
2. Representación del Lenguaje (Embeddings)
La investigación en NLP impulsa cómo las palabras o tokens se representan numéricamente.
Los transformers utilizan embeddings que capturan relaciones semánticas entre palabras.
Por ejemplo:
“King” y “queen” terminan cerca en el espacio vectorial debido a un uso contextual similar.
Esta idea proviene de la investigación sobre aprendizaje de representaciones en NLP.
Los embeddings traducen el significado en geometría.
El significado se convierte en distancia en el espacio vectorial.
3. Diseño del Objetivo de Entrenamiento
La tarea de entrenamiento en sí se origina en NLP.
La predicción del siguiente token es fundamentalmente una tarea de modelado de lenguaje, un problema central de NLP.
Otros objetivos inspirados en NLP incluyen:
- Modelado de lenguaje enmascarado
- Predicción secuencia a secuencia
- Completado de texto
La arquitectura aprende cualquier objetivo que definamos.
NLP define ese objetivo para tareas de lenguaje.
El objetivo determina qué tipo de inteligencia emerge.
4. Diseño de Arquitectura del Modelo
Los transformers se introdujeron originalmente para tareas de NLP como la traducción.
La atención se introdujo antes en la traducción automática neuronal y posteriormente se convirtió en el mecanismo central de la arquitectura transformer.
Por lo tanto, NLP influyó no solo en el entrenamiento sino también en la arquitectura misma.
El transformer nació para resolver problemas de lenguaje.
5. Instruction Tuning y Alineación
Al entrenar modelos conversacionales, se utilizan conjuntos de datos adicionales de NLP:
- Conjuntos de datos de diálogo humano
- Conjuntos de datos de preguntas y respuestas
- Ejemplos de resumen de texto
Todas estas son tareas de NLP que moldean el comportamiento del modelo.
Esta etapa alinea la capacidad bruta de modelado de lenguaje con una interacción útil.
La predicción bruta se convierte en conversación estructurada.
6. Evaluación y Benchmarking
La investigación en NLP proporciona benchmarks y marcos de evaluación.
- Benchmarks de comprensión del lenguaje
- Precisión de traducción
- Tareas de razonamiento y comprensión
Sin los marcos de evaluación del NLP, no sabríamos si el modelo realmente comprende el lenguaje.
La medición define el progreso.
Modelo Mental Simple
Para hacer todo más concreto:
- El machine learning proporciona los métodos de aprendizaje.
- Las redes neuronales proporcionan la estructura matemática.
- El transformer proporciona la nueva arquitectura.
- El NLP define cómo se procesan, entrenan y evalúan los datos de lenguaje.
Así que NLP interviene:
- Antes del entrenamiento (procesamiento de datos)
- Durante el entrenamiento (objetivos y representación)
- Después del entrenamiento (evaluación y alineación)
El machine learning enseña a los modelos a aprender. El NLP les enseña qué significa comprender el lenguaje.
Cómo Funciona un LLM en Producción
Un Modelo de Lenguaje de Gran Escala opera como parte de un sistema de software en capas donde distintos componentes gestionan la ejecución, el rendimiento y la interacción. El transformer entrenado en sí mismo no es una aplicación independiente. En su lugar, es activado y controlado por un motor de inferencia, que actúa como el entorno de ejecución responsable de convertir los weights del modelo en respuestas activas.
Cuando llega una solicitud, el motor de inferencia carga el modelo transformer y gestiona cómo se realizan los cálculos en GPUs. Asigna memoria, programa cargas de trabajo, ejecuta el forward pass de la red neuronal y genera tokens paso a paso según estrategias de muestreo definidas. Infraestructura circundante como APIs o plataformas de orquestación gestiona el tráfico y el escalado, mientras que el motor de inferencia se centra específicamente en la ejecución eficiente del modelo.
Conceptualmente, la estructura interna del entorno de inferencia puede entenderse como:
Motor de Inferencia
├── Modelo Transformer
├── Capa de Ejecución GPU
├── Gestor de Memoria
├── Scheduler
└── Lógica de Muestreo
→ El motor de inferencia incluye la lógica de ejecución y orquestación.
→ El modelo transformer contiene los archivos de weights entrenados y la configuración de la arquitectura.
→ La lógica de muestreo gestiona la estrategia de selección de tokens.
Juntos, estos componentes garantizan que el texto entrante sea procesado a través de la arquitectura transformer, ejecutado eficientemente en hardware y devuelto como salida generada en tiempo real.
Perspectiva Final
Cuando alguien dice “LLM”, se refiere al producto final de todo un stack.
Si eliminas una capa, el sistema colapsa.
Mantén clara la jerarquía y la arquitectura se vuelve simple:
Inteligencia Artificial → Machine Learning → Redes Neuronales → Redes Neuronales Profundas / Deep Learning → Arquitectura Transformer → Entrenamiento a Gran Escala → Modelo Fundacional → LLM
Si añades NLP a lo largo de todo el proceso, el modelo se vuelve consciente del lenguaje.
El machine learning es la disciplina utilizada para construir el coche. Los transformers son el motor dentro de él. Los datos son el combustible que lo hace funcionar. El NLP es el sistema de navegación que le indica hacia dónde ir.
→ Esta analogía ayuda a ilustrar la clara distinción entre métodos, arquitecturas y dominios de aplicación.
Referencias Claves
-
Attention Is All You Need
Artículo de investigación original que introduce la arquitectura Transformer y el mecanismo de auto-atención que impulsa los modelos modernos de lenguaje de gran escala. -
Language Models are Few Shot Learners
Artículo de OpenAI que presenta GPT-3 y demuestra cómo los modelos de lenguaje a gran escala pueden realizar tareas con ejemplos mínimos. -
Scaling Laws for Neural Language Models
Investigación que explica cómo el rendimiento del modelo mejora a medida que aumentan los datos de entrenamiento, el cómputo y el tamaño del modelo. -
Speech and Language Processing (Stanford NLP Book) — Daniel Jurafsky & James H. Martin
Libro académico completo que cubre los fundamentos del procesamiento del lenguaje natural, el modelado del lenguaje y las técnicas modernas de NLP. -
On the Opportunities and Risks of Foundation Models
Artículo de investigación de Stanford que introduce el concepto de modelos fundacionales y analiza sus implicaciones técnicas y sociales. -
The Illustrated Transformer — Jay Alammar
Una explicación visual ampliamente utilizada de la arquitectura Transformer y los mecanismos de atención.






Frank
February 28, 2026La IA permite a los desarrolladores ir más allá de las integraciones codificadas de forma rígida y convertirse en habilitadores estratégicos de la tecnología.
Frank
February 28, 2026La IA permite que un equipo de dos opere como un equipo de veinte.
Frank
February 28, 2026La IA está aquí para ampliar las capacidades humanas, cambiando la conversación del miedo al desplazamiento laboral hacia el entusiasmo por la transformación del trabajo. Al ampliar el trabajo humano con inteligencia artificial, desbloqueamos menores costos, innovación más rápida y una ventaja competitiva que otros no pueden igualar.
Frank
February 28, 2026La IA no está aquí para reemplazarnos, está aquí para resolver los problemas que surgen cuando intentamos pasar del punto A al punto B, C o más allá. Aborda los desafíos, las limitaciones, los errores y las ineficiencias que han acompañado el progreso humano a lo largo de la historia, hasta este momento, cuando la IA pasa a formar parte de la solución.